
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- python
- TAIL
- uname
- V100
- ifconfig
- docker
- 우분투 22.04 패스워드 초기화
- grub
- sysstat
- TensorFlow
- dmesg
- 리눅스 기본명령어
- 우분투
- 엔비디아 도커
- netplan
- Ubuntu 22.04
- nvidia-docker
- NGC
- sudoer
- 도커
- Cat
- 모니터링
- 패스워드초기화
- ethtool
- CUDA
- nvidia
- passwd
- A100
- 도커 설치
- 우분투패스워드초기화
- Today
- Total
또이리의 Server Engineer
Nvidia Tesla A100 - 8GPU error Xid 61 본문
Nvidia Tesla A100 - 8GPU error Xid 61
A100 tensorflow, dcgmi error(AMD server)
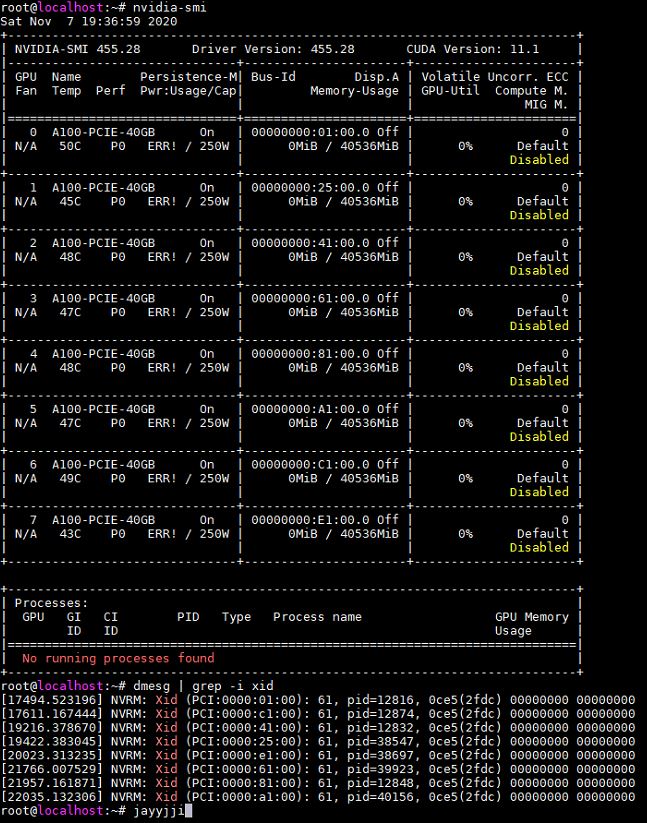
gpu-burn을 돌렸을 때는 이상이 없는데, tensorflow benchmarks나 dcgmi diag를 돌렸을 때는 gpu가 한 개씩 에러가 나면서 결국 8개 다 error가 발생합니다.
도대체 이유를 모르겠습니다.
텐서 플로우는 로컬에서 호환되는 빌드 버전을 아직 찾지 못해서 nvidia driver, bazle, cuda, cudnn, tensor flow 버전별로 테스트하고 있습니다.
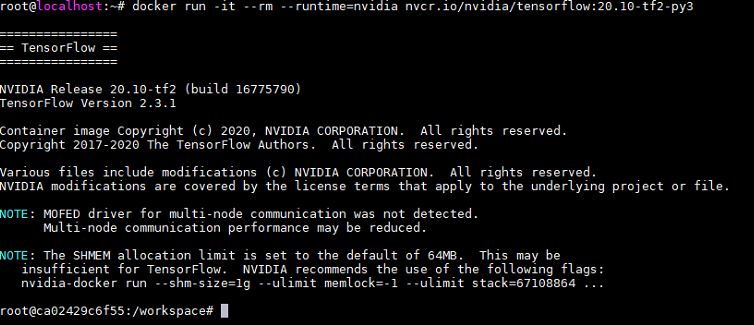
우선 급한 데로 엔비디아 도커에 이미지를 받아서 tensorflowtensorflow benchmarks 실행했는데도 dcgmi와 같은 xid 61 에러가 순차적으로 발생합니다. 증상은 tensorflow ver1과 ver2 동일합니다.
pci-e 4.0 slot을 test 하기 위해서 AMD GPU server가 입고 됐는데, 왠지 AMD 시스템이라 그런 것 같기도 합니다.
오늘 (2020-11-12) 인텔 CPU를 사용하는 pci-e 3.0 slot의 server에 A100을 옮겨서 테스트했더니, 해당 증상이 나타나지 않았다는 결과를 들었기 때문에 더한 거 같습니다.
tesla A100 multi GPU에 관한 자료가 너무 없어서 난감한 상황입니다...
Xid 61로 봐서는 하드웨어 불량은 아닌 것 같습니다.
해결되면 후기 올리겠습니다.
2020-11-13 일 후기 입니다. 제조사에서 BIOS setting에 관한 메일을 받아서 test 해보았습니다.
NUMA, SMT, TPD 등 관련 설정이 있었지만, IOMMU 문제였던 것 같습니다.
BIOS에서 NB configuration - IOMMU = AUTO -> Disabled로 변경한 후, Xid 61 증상은 없어졌습니다.
nvidia-docker에서 tensorflow benchmarks도 정상 실행됩니다.
추가적으로 IOMMU Disable 이후 cuda sample test에서 P2P bandwidth와 Latency 부분도 정상적으로 test 진행됩니다.
local에 tensorflow build 후 test 종료할 예정입니다.
간략하게 IOMMU를 알아보겠습니다.
IOMMU(Input Output Memory Management Unit)
IOMMU는 다음과 같은 기능을 합니다.
Transalation 디바이스(IO 또는 BUS) 주소를 물리 주소로 변환할 수 있도록 매핑을 제공합니다. DMA에 사용하는 buffer는 연속된 물리 주소여야 합니다. IOMMU를 사용하는 경우에는 그러한 제한이 없어집니다.
IOMMU가 MMU와는 별도의 매핑 테이블을 사용합니다. 그렇기 때문에 시스템 메모리에 페이지가 연속되지 않아도 됩니다.
Isolation 메모리에 대한 디바이스의 접근 제어를 제공합니다.
IO Virtualization 가상화를 지원하며 디바이스가 별개의 DMA 가상 주소 공간을 사용할 수 있습니다. CPU에 있는 MMU도 가상화를 위해 별개의 MMU가 있는 것처럼 IOMMU도 이와 유사합니다.
메모리 할당제한과 성능
IOMMU를 사용하면 디바이스가 물리 메모리의 전체 영역을 사용할 수 있기 때문에 대용량 버퍼를 구성할 수 있습니다. IOMMU의 매핑 테이블을 사용하여 디바이스가 분산된 물리 메모리에 접근할 수 있습니다.
DMA 버퍼 용도로 분산된 물리 메모리를 할당받고, IOMMU의 매핑 테이블을 이용하여 디바이스가 하나의 연속된 가상 주소에 액세스 할 수 있습니다.
물리 메모리의 주소 영역이 4G를 초과하는 64비트 시스템에서 IOMMU를 32비트 모드를 사용하는 경우 시스템 메모리의 모든 영역에 버퍼를 만들 수가 없습니다.
이러한 경우에도 swiotlb 방법을 사용하므로 이때에도 성능이 저하됩니다. 그러나 점점 64비트 IOMMU 모드를 사용하는 방법으로 migration 하므로 점점 찾아볼 수 없어집니다.
대표적인 IOMMU
Intel North Bridge에 VT-D(Virtualization Technology for Directed I/O)를 채용, IO 허브 제공, 가상화 지원
AMD dual IOMMU를 채용, IO 허브 제공, 가상화 지원
ARM 및 ARM64 여러 버전의 SMMU가 제공, 가상화 지원
PCI-SIG 내부 IOMMU, I/O 가상화 (IOV)와 Address Translation Services (ATS) 기능 제공
Nvidia 카드 내부 GARTGraphics Address Remapping Table라는 IOMMU 존재, 가상화 지원
'Linux Engineer' 카테고리의 다른 글
| 우분투 스트레스 테스트 - 모니터링 (0) | 2020.11.11 |
|---|---|
| 우분투 18.04 엔비디아 도커 - 텐서플로우 설치 (0) | 2020.11.09 |
| 우분투 18.04 도커 설치 (0) | 2020.11.08 |
| 리눅스 grep 명령어 (0) | 2020.11.06 |
| GeForce RTX 3080 vs RTX 3090 (0) | 2020.11.04 |



